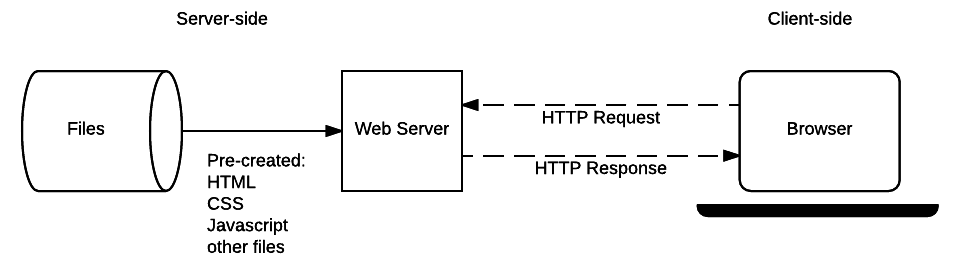
As we learned earlier in this text, in the client-server architecture, a server provides services to clients that exchange information with it.
Clients and servers communicate by exchanging two types of messages (as opposed to a stream of data). The messages sent by the client, such as a Web browser, are called requests and the messages sent by the server as an answer are called responses.
Various types of servers and clients are part of this ecosystem. A web server provides information in response to the query sent by its clients. A print server prints documents sent as queries by the client. When queried, an email server forwards email messages to the designated recipient, while a music server delivers the music requested to the client.
Networked applications do not exchange random messages. In order to ensure that the server is able to understand the queries sent by a client, and also that the client is able to understand the responses sent by the server, they must both agree on a set of syntactic and semantic rules. These rules define the format of the messages exchanged as well as their ordering. This set of rules at the application layer make up an application-level protocol.
An application-level protocol is similar to a structured conversation between humans. Assume that Alice wants to know the current time but does not have a watch. If Bob passes close by, the following conversation could take place:
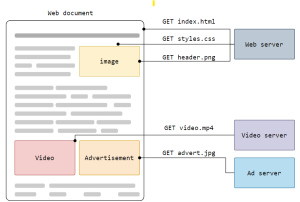
Request messages are sent by the client to the server to ask for a service or a resource. Response messages are sent by the server to the client to provide the requested service or resource, or to indicate an error or a status. For example, in the HTTP protocol, the client sends a GET request message to the server to ask for a web page, and the server sends a response message with the web page content or an error code. A complete document is reconstructed from the different sub-documents fetched, for instance, text, layout description, images, videos, scripts, and more.
Most applications exchange strings that are composed of fixed or variable numbers of characters. A common solution to define the character strings that are acceptable is to define a grammar using a Backus-Naur Form (BNF) such as the Augmented BNF defined in RFC 5234. A BNF is a set of production rules that generate all valid character strings, and describes the rules and formats (i.e., the syntax) for exchanging messages between applications on different hosts. BNF can help to ensure that the messages are well-formed and unambiguous, and that they can be parsed and interpreted correctly by the applications. BNF can also help to document and standardize application protocols, making them easier to understand and implement by different parties. BNF is widely used to describe the syntax of many common application protocols. We will cover a few of these in this chapter.
Some common application layer protocols include HTTP, DNS, DHCP, FTP, SMTP SNMP, IMAP/POP, and FTP. HTTPS, TLS, SSL, and DNSSEC are also related to application layer protocols, enabling encryption and authentication between applications on different hosts.
Hypertext Transfer Protocol (HTTP) is a text-based protocol that governs the movement of web traffic and is the foundation of any data exchange on the Web. A typical request has a method and a path, such as GET /index.html , which retrieves the landing page of a website. Responses have a response code, message, and optionally, some data.
Both requests and responses can take advantage of headers, arbitrary lines of text following the initial request or response. Because headers were designed to be open-ended, many new headers have been added over time. A modern web request/response usually has far more information in the headers than just the basics defined in HTTP 1.1.
HTTP messages, as defined in HTTP/1.1 and earlier, are human-readable. In HTTP/2, these messages are embedded into a binary structure, called a frame , allowing optimizations such as the compression of headers and multiplexing. Even if only part of the original HTTP message is sent in this version of HTTP, the semantics of each message is unchanged and the client reconstitutes (virtually) the original HTTP/1.1 request. Therefore, we find it useful to comprehend HTTP/2 messages in the HTTP/1.1 format.
Unencrypted HTTP traffic is sent over port 80 and is vulnerable to attack as all information is sent in cleartext.
When a client wants to communicate with a server, either the final server or an intermediate proxy, it performs the following steps:
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html DOCTYPE html>… (here come the 29769 bytes of the requested web page)
Below is the format of an example HTTP request:

Requests consist of the following elements:
Below is the format of an HTTP response:

Responses consist of the following elements:
Some standard response codes are shown below.
Internal Server Error
Table 7-1: Standard HTTP error codes
Hypertext Transfer Protocol Secure (HTTPS) solves the problem of unencrypted traffic by wrapping HTTP requests in TLS, which we will cover at the end of this section. HTTPS traffic uses port 443 and is typically signified in a browser with a lock icon in the upper left-hand corner. By clicking on the icon, users can learn more about the certificates being used for communication. Utilizing a robust PKI (public key infrastructure), HTTPS allows for safe HTTP communication between client and server.
While addresses are natural for the network and transport layer entities, humans prefer to use names when interacting with network services. Names can be encoded as a character string and a mapping service allows applications to map a name into the corresponding address. Using names is friendlier for humans, but it also provides a level of indirection that is very useful in many situations. The Domain Name System (DNS) is used to resolve domain names to IP addr esses. Domain names are the simple website names to which we are accustomed, and significantly easier for people to remember than IP addresses. In order for a computer to resolve a name, it first queries a local cache, then its primary DNS server. Assuming the DNS server cannot find the name, it will query a root server for a top level domain (TLD) server, which maintains a listing of authoritative nameservers for that particular domain (edu, com, net, org, gov, etc.). Finally once an authoritative nameserver is found, it will respond with the IP address for that particular hostname, which will be cached and sent back through the user’s primary DNS server to the user.
While RFC 819 discussed the possibility of organizing the names as a directed graph, the Internet opted for a tree structure to contain all names. In this tree, the top-level domains are those that are directly attached to the root. The set of top-level domain-names is managed by the Internet Corporation for Assigned Names and Numbers ( ICANN ), which holds ongoing discussions to increase the number of top-level domains.
Each top-level domain is managed by an organization that decides how sub-domain names can be registered. Most top-level domain names use a first-come first served (FCFS) system, and allow anyone to register domain names, but there are some exceptions. For example, .gov is reserved for the United States government, and .int is reserved for international organizations.
Watch an overview for the DNS tree structure by Barry Brown (CC-BY).
The syntax of the domain names has been defined more precisely in RFC 1035. This document recommends the following BNF for a fully qualified domain name (the domain names themselves have a much richer syntax).
domain :: = subdomain | ” “subdomain ::= label | subdomain "." label label ::= letter [ [ ldh-str ] let-dig ] ldh-str ::= let-dig-hyp | let-dig-hyp ldh-str let-dig-hyp ::= let-dig | "-" let-dig ::= letter | digit letter ::= any one of the 52 alphabetic characters A through Z in upper case and a through z in lowercase digit ::= any one of the ten digits 0 through 9
This grammar specifies that a host name is an ordered list of labels separated by the dot ( . ) character. Each label can contain letters, numbers and the hyphen character ( – ). Fully qualified domain names are read from left to right. The first label is a hostname or a domain name followed by the hierarchy of domains and ending with the root implicitly at the right. The top-level domain name must be one of the registered TLDs.
The Domain Name System was created at a time when the Internet was mainly used in North America. The initial design assumed that all domain names would be composed of letters and digits RFC 1035 . As Internet usage grew in other parts of the world, it became important to support non-ASCII characters. For this, extensions have been proposed to the Domain Name System RFC 3490 . In a nutshell, the solution that is used to support Internationalized Domain Names works as follows. First, it is possible to use most of the Unicode characters to encode domain names and hostnames, with a few exceptions (for example, the dot character cannot be part of a name since it is used as a separator). Once a domain name has been encoded as a series of Unicode characters, it is then converted into a string that contains the xn-- prefix and a sequence of ASCII characters. More details on these algorithms can be found in RFC 3490 and RFC 3492 .
The possibility of using all Unicode characters to create domain names opened a new form of attack called the homograph attack. This attack occurs when two character strings or domain names are visually similar but do not correspond to the same server. A simple example is https://G00GLE.COM and https://GOOGLE.COM. These two URLs are visually close but they correspond to different names (the first one does not point to a valid server). With other Unicode characters, it is possible to construct domain names that are visually equivalent to existing ones.
How do client hosts or applications retrieve the mapping for a given name?
DNS resolution of namespaces is the process of finding the IP address of a host based on its domain name. A domain name is a human-readable name that identifies a host on a network, such as www.example.com. Each nameserver stores part of the distributed database and answers the queries sent by clients. There is at least one nameserver that is responsible for each domain. A sub-domain may contain both host names and sub-domains. A namespace is a collection of domain names that are organized in a hierarchical tree structure, such as the DNS namespace. The DNS namespace consists of different levels of domains, such as top-level domains (TLDs), second-level domains, and subdomains. Each domain has one or more name servers that store information about the hosts in that domain. For example, the name server for the .com TLD stores information about all the second-level domains that end with .com, such as example.com.
To resolve a domain name into an IP address, a client needs to query a DNS server. The DNS server can be either a recursive resolver or an authoritative server. A recursive resolver is a server that acts as an intermediary between the client and the authoritative servers. It follows a chain of referrals from the root nameserver to the TLD server to the authoritative server for the queried domain name, and returns the IP address to the client. An authoritative server is a server that hosts a zone, which is a portion of the DNS namespace. It can answer queries for any name in its zone directly, without contacting other servers.
For example, suppose a client wants to resolve www.cnet.com into an IP address. The client sends a query to its recursive resolver, which then contacts the root nameserver for the DNS namespace. The root nameserver responds with a referral to the .com TLD server. The recursive resolver then contacts the .com TLD server, which responds with a referral to the cnet.com authoritative server. The recursive resolver then contacts the cnet.com authoritative server, which responds with the IP address of www.cnet.com. The recursive resolver then sends the IP address back to the client, which can then connect to the host.
DNS resolvers have several advantages over letting each Internet host directly query nameservers. Firstly, regular Internet hosts do not need to maintain the up-to-date list of the addresses of the root servers. Secondly, regular Internet hosts do not need to send queries to nameservers all over the Internet. Furthermore, as a DNS resolver serves a large number of hosts, it can cache the received answers. This allows the resolver to quickly return answers for popular DNS queries and reduces the load on all DNS servers [JSBM2002].
See how DNS resolution works, step by step, in this video by Barry Brown (CC-BY).
In addition to being more human friendly, using names instead of addresses inside applications has several important benefits. Let’s consider a popular application that provides information stored on servers. The server provides information upon requests from client processes. A first deployment of this application would be to rely only on addresses. In this case, the server process would be installed on one host and the clients would connect to this server to retrieve information. Such a deployment has several drawbacks :
Using names solves these problems. In addition, if the clients are configured with the name of the server, they will query the name service before contacting the server. The name service will resolve the name into the corresponding address. If a server process needs to move from one physical server to another, it suffices to update the name to address mapping on the name service to allow all clients to connect to the new server. The name service also enables the servers to better sustain the load. Assume a very popular server is accessed by millions of users. This service cannot be provided by a single physical server due to performance limitations. Thanks to the utilization of names, it is possible to scale this service by mapping a given name to a set of addresses.
When a client queries the name service with the server’s name, the name service returns one of the addresses in the set. Various strategies can be used to select one particular address inside the set of addresses. A first strategy is to select a random address in the set. A second strategy is to maintain information about the load on the servers and return the address of the less loaded server. Note that the list of server addresses does not need to remain fixed. It is possible to add and remove addresses from the list to cope with load fluctuations. Another strategy is to infer the location of the client from the name request and return the address of the closest server.
Mapping a single name onto a set of addresses allows popular servers to dynamically scale. There are also benefits in mapping multiple names, possibly a large number of them, onto a single address. Consider the case of information servers, in which some of the servers attract only a few clients per day. Using a single physical server for each of these services would be a waste of resources. A better approach is to use a single server for a set of services that are all identified by different names. This enables service providers to support a large number of server processes, identified by different names, onto a single physical server. If one of these server processes becomes very popular, it will be possible to map its name onto a set of addresses to be able to sustain the load. This can be done dynamically if needed.
Names provide a lot of flexibility compared to addresses. For the network, they play a similar role as variables in programming languages. No programmer using a high-level programming language would consider using hardcoded values instead of variables. For the same reasons, all networked applications depend on names and abstract the addresses as much as possible.
The official list of top-level domain names is maintained by IANA at http://data.iana.org/TLD/tlds-alpha-by-domain.txt . Until February 2008, the root DNS servers only had IPv4 addresses. IPv6 addresses were slowly added to the root DNS servers to avoid creating the problems discussed in http://www.icann.org/en/committees/security/sac018.pdf . As of February 2021, a few DNS root servers are still not reachable using IPv6. The full list is available at http://www.root-servers.org/.
DNS operates mostly via UDP on port 53. This means that although DNS is designed to be resilient and decentralized, the traffic is not authenticated or encrypted . This has made it a target for MitM attacks. Likewise, cache hits and misses can yield information as to what names have been recently resolved (e,g., as with the Sony Rootkit). The recursive nature of DNS has also allowed for DoS attacks in the past, but much of that has been solved by limiting recursive queries to the user-facing DNS servers (i.e., the one given to you by your DHCP request).